ผลต่างระหว่างรุ่นของ "204512-53/lecture4"
| แถว 37: | แถว 37: | ||
เมื่อเรารวม P (probability function) กับ sample space ก็จะเรียกว่า probability space ก็คือผลลัพธ์ทั้งหมดที่เป็นได้พร้อมกับค่าที่ระบุติดกับ outcome แต่ละอัน ที่ค่านี้มีคุณสมบัติบางอย่าง (ความน่าจะเป็นที่ได้ outcome แต่ละอัน) ในการวิเคราะห์ต่อไป หลายๆ ครั้งที่ outcome แต่ละอันมีความน่าจะเป็นที่เท่าๆ กัน คือเป็น uniform distribution ดังนั้นความน่าจะเป็นของ event ก็จะใช้การนับ แต่บางครั้งความน่าจะเป็นแต่ละอันก็ไม่เท่ากันก็ได้<br /> | เมื่อเรารวม P (probability function) กับ sample space ก็จะเรียกว่า probability space ก็คือผลลัพธ์ทั้งหมดที่เป็นได้พร้อมกับค่าที่ระบุติดกับ outcome แต่ละอัน ที่ค่านี้มีคุณสมบัติบางอย่าง (ความน่าจะเป็นที่ได้ outcome แต่ละอัน) ในการวิเคราะห์ต่อไป หลายๆ ครั้งที่ outcome แต่ละอันมีความน่าจะเป็นที่เท่าๆ กัน คือเป็น uniform distribution ดังนั้นความน่าจะเป็นของ event ก็จะใช้การนับ แต่บางครั้งความน่าจะเป็นแต่ละอันก็ไม่เท่ากันก็ได้<br /> | ||
| − | |||
'''วิเคราะห์ ในกรณี ball and bin'''<br /> | '''วิเคราะห์ ในกรณี ball and bin'''<br /> | ||
| แถว 45: | แถว 44: | ||
##กรณี m = n ความน่าจะที่เกิดการชนกันคือ เนื่องจากทุก outcome มีความน่าจะเป็นที่เท่ากัน ความน่าจะเป็นที่จะได้ outcome ใดๆ คือ 1/<math>n^m</math> ถ้า n = m ความน่าจะเป็นที่ไม่มี collision ลูกบอลลูกแรกมี n ทางเลือก ลูกที่สองมี n-1 ทางเลือก... ดังนั้น outcome ที่ไม่มี collision คือ n! จาก sample space <math>n^n</math> ได n!/ <math>n^n</math> ซึ่งมีค่าน้อยมากๆ กรณี n มีค่ามากขึ้น ซึ่งสามารถแสดงได้ว่า n!/ <math>n^n</math> ≤ 1/<math>2^{n/2}</math> | ##กรณี m = n ความน่าจะที่เกิดการชนกันคือ เนื่องจากทุก outcome มีความน่าจะเป็นที่เท่ากัน ความน่าจะเป็นที่จะได้ outcome ใดๆ คือ 1/<math>n^m</math> ถ้า n = m ความน่าจะเป็นที่ไม่มี collision ลูกบอลลูกแรกมี n ทางเลือก ลูกที่สองมี n-1 ทางเลือก... ดังนั้น outcome ที่ไม่มี collision คือ n! จาก sample space <math>n^n</math> ได n!/ <math>n^n</math> ซึ่งมีค่าน้อยมากๆ กรณี n มีค่ามากขึ้น ซึ่งสามารถแสดงได้ว่า n!/ <math>n^n</math> ≤ 1/<math>2^{n/2}</math> | ||
#โดยเฉลี่ยแล้วมีถังว่างกี่ถัง ต้องการหาจำนวนถังว่างซึ่งเป็นตัวแปรสุ่ม ซึ่งจะไม่มีค่าจนกว่าจะได้ทำการทดลอง แต่เราสามารถพูดถึงคุณสมบัติบางอย่างได้บ้างเหมือนกันแม้ว่าจะไม่ได้ทดลอง เวลาพูดถึงตัวแปรสุ่มมีคุณสมบัติอย่างหนึ่งที่มีความหมายคือ ค่า Expectation ของมัน (หรืออาจเรียกว่า ค่าเฉลี่ยตัวแปรสุ่ม)<br /> | #โดยเฉลี่ยแล้วมีถังว่างกี่ถัง ต้องการหาจำนวนถังว่างซึ่งเป็นตัวแปรสุ่ม ซึ่งจะไม่มีค่าจนกว่าจะได้ทำการทดลอง แต่เราสามารถพูดถึงคุณสมบัติบางอย่างได้บ้างเหมือนกันแม้ว่าจะไม่ได้ทดลอง เวลาพูดถึงตัวแปรสุ่มมีคุณสมบัติอย่างหนึ่งที่มีความหมายคือ ค่า Expectation ของมัน (หรืออาจเรียกว่า ค่าเฉลี่ยตัวแปรสุ่ม)<br /> | ||
| − | + | สำหรับตัวแปรสุ่ม x ใดๆ <br /> | |
| − | + | <math>E[x] = \sum_{i=-\infty}^\infty 1×Pr[x=i]</math>:ในการค่าค่า expectation ของจำนวนถังว่างเมื่อมี n ถังลูกบอล m ลูก จะยากมาก เนื่องจากมันขึ้นต่อกันอยู่ ในการวิเคราะห์ จะใช้คุณสมบัติที่สำคัญของ expectation คือ linearity of expectation คือ<br /> | |
| − | :ในการค่าค่า expectation ของจำนวนถังว่างเมื่อมี n ถังลูกบอล m ลูก จะยากมาก เนื่องจากมันขึ้นต่อกันอยู่ ในการวิเคราะห์ จะใช้คุณสมบัติที่สำคัญของ expectation คือ linearity of expectation คือ<br /> | + | สำหรับตัวแปรสุ่ม x,y ใดๆ จะขึ้นต่อกันก็ได้ หรือไม่ขึ้นต่อกันก็ได้ เช่นจำนวนถังว่าง กับจำนวนถังที่ไม่ว่าง<br /> |
| − | + | <math>E[x+y]=E[x]+E[y]</math><br /> | |
| − | + | วิเคราะห์หาจำนวนถังว่างเมื่อจำนวนถังเท่ากับจำนวนลูกบอล นิยามตัวแปรสุ่ม ให้ ตัวแปรสุ่ม x แทนจำนวนถังว่าง ให้ตัวแปรสุ่ม xi แทนจำนวนถังว่าง<br /> | |
| + | <math> | ||
| + | ตัวแปรสุ่ม x_i = | ||
| + | \begin{cases} | ||
| + | 1 ถ้าถัง i ว่าง \\ | ||
| + | 0 ในกรณีอื่นๆ | ||
| + | \end{cases} | ||
| + | </math> | ||
รุ่นแก้ไขเมื่อ 18:29, 9 สิงหาคม 2553
บันทึกคำบรรยายวิชา 204512-53 นี้ เป็นบันทึกที่นิสิตเขียนขึ้น เนื้อหาโดยมากยังไม่ผ่านการตรวจสอบอย่างละเอียด การนำไปใช้ควรระมัดระวัง
จดบันทึกคำบรรยายโดย:
นายกฤตกรณ์ ศรีวันนา G5314550024 นายณัฐพล จารุพัฒนะสิริกุล G5314550067 นายพงศกร สุระธรรม G5314550130 นายวุฒิชัย วภักดิ์เพชร G5314550181
Hashing
มี key กับ value K ∈{0,1,…,M-1} M มีค่าเยอะมากๆ ปกติแล้วถ้ามีข้อมูล n ตัว จะใช้ array เก็บ n ช่อง หรือ cn ช่อง (เมื่อ c เป็นค่าคงที่) ให้ m เป็นขนาดของ array หรือขนาดของ table ซึ้ง m >= n
มี hash function h ที่รับ k เข้าไปแล้วทำการ map ไป space ของ table(0,1,…,m-1) เมื่อเรารู้ค่า key เราก็จะรู้ว่าจะไปหาข้อมูลที่ ช่องไหน ถ้าข้อมูลที่แตกต่างกันลงกันคนละช่อง table ก็เปรียบเป็น array นั้นเอง เรื่องที่สนในการทำ Hashing มีสองเรื่องคือ 1. วิธีหรือฟังก์ชันที่ใช้ในการคำนวณหาค่าที่ตำแหน่งที่ใช้เก็บข้อมูล 2. การแก้ปัญหาเมื่อเกิดการชนกันเกิดขึ้น ตัวอย่างการแก้ปัญหาเมื่อเกิดการชนกันคือ การใช้วิธี chaining ในการแก้ปัญหาการชนกันโดยการใช้ link list มาใช้เก็บข้อมูลที่ชนกันตามภาพด้านล้าง หรือแก้โดยวิธี open addressing คือข้อมูลที่ชนกันจะถูกเก็บลงในช่องถัดไปที่ว่าง ตามภาพด้านล้าง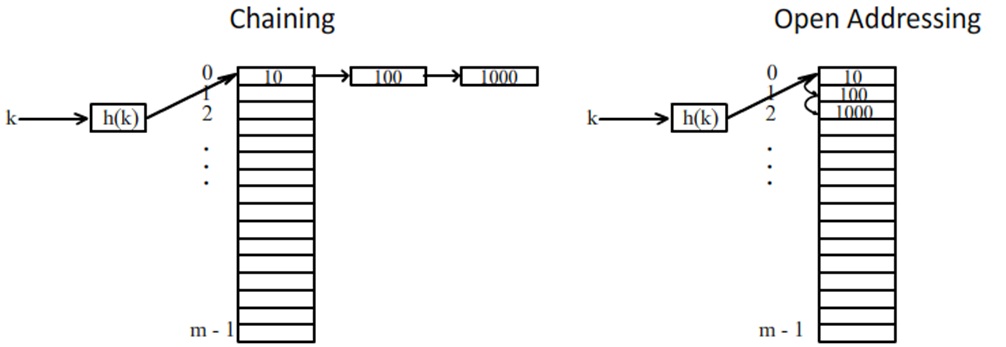
การวิเคราะห์ปัญหาการใช้ hash สิ่งแรกคือ วิเคราะห์ว่า hash function นั้นดี ซึ่งมีอยู่จริงแต่อาจไม่ดีสำหรับสำหรับทุกๆ input สำหรับ hash function ที่ดีนั้นควรจะมีการสุ่มแบบกระจาย สำหรับการวิเคราะห์จะอาศัยการวิเคราะห์ของการทดลองตระกูล Ball and Bin
Ball and Bin
มีถัง n ถัง ลูกบอล m ลูก โยนลูกบอลไปสุ่มๆ ลงถังไหนก็ได้ด้วยความน่าจะเป็นที่เท่ากัน สิ่งที่สนใจคือ
- ถังที่มีลูกบอลมากกว่า 1 ลูก
- จำนวนถังว่าง
- จำนวนลูกบอลในถังที่มีจำนวนมากที่สุด
ในการเรียนความน่าจะเป็น หรือการทดลองแบบสุ่มจำเป็นต้องเข้าใจ ศัพท์ต่างๆ ดังนี้ Random experiment คือการทดลองแบบสุ่ม ซึ่งจะได้ผลลัพธ์ออกมาคือ outcome outcome เป็นสิ่งที่สังเกตได้ ซึ่งในการทดลองแต่ละครั้งก็จะได้ outcome ออกมาหลายๆ อัน เซตของ outcome ทั้งหมดที่เป็นไปได้ เรียกว่า sample space ตามภาพด้านล่าง
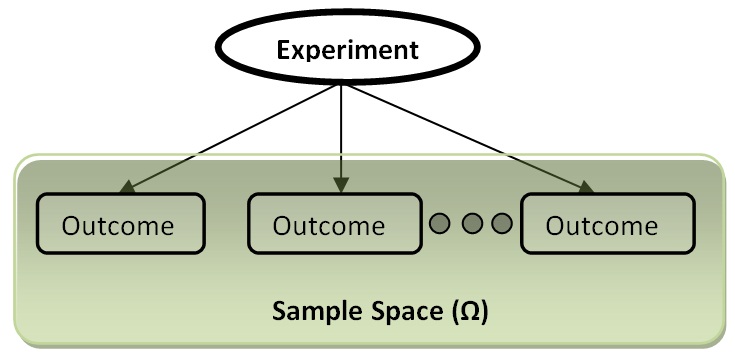
ปกติเราไม่ได้สนใจไปที่ outcome โดยแท้จริง เพราะ outcome มีอยู่ได้เยอะแยะ บางครั้งเราสนใจคุณสมบัติบางอย่างของ outcome เช่น
นิยาม experiment ในกรณี ball and bin มีถัง n ถังลูกบอล m ลูก ลูกบอลแต่ละลูกโยนเป็นอิสระต่อกัน ความน่าจะเป็นที่ลูกบอลแต่ละลูกลงถังๆ หนึ่งคือ 1/n
จากการทดลองก็จะได้ว่าลูกบอลลูกที่ 1 ลงถังไหน ลูกบอลลูกที่ 2 ลงถังไหน… ซึ่ง Outcome ของเราขึ้นอยู่กับว่าความสังเกตได้ของเรา เช่นถ้าลูกบอลที่ 1 กับ 5 มีลักษณะเหมือนกัน แยกกันไม่ออก เซตของ outcome ก็จะเปลี่ยนไป sample space ก็จะเปลี่ยนไป แต่ถ้าการทดลองเรื่องเดียวกัน experiment วัดแบบเดียวกัน มันต้องได้ออกมาเหมือนกัน
จากการทดลองเราไม่ได้สนใจที่ outcome โดยแท้จริงแต่เราสนใจคุณสมบัติบางอย่างเช่น
- จำนวนถังที่มีลูกบอลมากว่า 1 ลูก
- จำนวนถังว่าง
- จำนวนลูกบอลในถังที่มากที่สุด
ซึ่งค่าเหล่านี้ถ้าไม่ทดลองจะไม่รู้ค่า เราจะรู้ค่าก็ต่อเมื่อเราทดลองเสร็จแล้วหรือเรามี outcome ออกมาแล้ว ค่าตรงนี้เปลี่ยนแปลงไปตามผลลัพธ์การทดลอง เราจะเรียกค่าตรงนี้หรือผลลัพธ์เหล่านี้ว่า random variable (ตัวแปรสุ่ม) ก็คือตัวแปรที่มีค่าเปลี่ยนแปลงไปตามผลลัพธ์ แต่ในความหมายหนึ่งในเชิงทางการแล้ว random variable เป็นฟังก์ชันจาก sample space ไปอะไรบางอย่าง Ω → R (มีค่าเป็นจำนวนจริง) เช่นจำนวนถังที่ว่าง ได้ outcome แล้วสามารถบอกได้เลยว่ามีถังว่างกี่อัน ถ้าไม่มี outcome ก็ไม่สามารถบอกได้ว่ามีถังว่างกี่อัน
ก่อนจะวิเคราะห์อะไรได้ เราต้องมีนิยาม experiment ที่ชัดเจนก่อน เราจะทดลองอะไร วัดอะไร ได้ผลลัพธ์เป็นอะไร จากตรงนั้นจะได้ว่า เซตของ outcome ทั้งหมดคือ sample space และจาก outcome เราก็ไปสนใจอีกว่า outcome นั้นมีค่าเป็นเท่าไหร่ นอกจากเราจะสนใจ random variable ธรรมดาแล้ว random variable บางชนิดมีผลลัพธ์เป็นจริง เท็จ เช่น random variable ที่ถามว่ามีลูกบอลลงครบทุกถังหรือไม่ หรือ มีถังไหนไหมที่มีลูกบอลลง 2 ลูก random variable ทีตอบแบบจริงเท็จ มีอีกชื่อหนึ่งคือ event คือเหตุการณ์เพราะฉะนั้นถ้าเราวงๆ เซตของ outcome ที่มันตอบจริง ก็มองตรงนี้ว่าเป็นเหตุการณ์ หรือ event กล่าวคือ event เป็นซับเซตของ outcome หรือมองอีกแง่หนึ่ง อาจมองเป็นฟังก์ชันก็ได้ ที่รับ outcome ไปแล้วตอบ Yes , No ก็คืออยู่ในซับเซตหรือไม่อยู่ในซับเซต
ในการนิยามความน่าจะเป็น จะมีเทอมอีกตัวหนึ่งคือ P ทีกำหนดค่าให้กับ outcome แต่ละอัน โดยที่ค่าที่กำหนดให้ outcome แต่ละอันจะมีลักษณะเป็นความน่าจะเป็นคือ ≥ 0, ≤ 1 ในการทดลองต้องมี outcome เกิดขึ้นดังนั้นถ้าเรา ∑ ของทุก outcome ก็จะได้ 1 ซึ่งนี้คือความน่าจะเป็นของแต่ละ outcome ซึ่งการนิยามแบบนี้จะเป็นแบบ discrete ถ้าความน่าจะเป็นที่เป็นแบบ continuous มันจะนิยามแบบนี้ไม่ได้
พอได้ความน่าจะเป็นแต่ละจุด ก็มองเป็นความน่าจะเป็นของ event ได้ ก็คือความจะเป็นของแต่ละจุดใน event ร่วมกัน
เมื่อเรารวม P (probability function) กับ sample space ก็จะเรียกว่า probability space ก็คือผลลัพธ์ทั้งหมดที่เป็นได้พร้อมกับค่าที่ระบุติดกับ outcome แต่ละอัน ที่ค่านี้มีคุณสมบัติบางอย่าง (ความน่าจะเป็นที่ได้ outcome แต่ละอัน) ในการวิเคราะห์ต่อไป หลายๆ ครั้งที่ outcome แต่ละอันมีความน่าจะเป็นที่เท่าๆ กัน คือเป็น uniform distribution ดังนั้นความน่าจะเป็นของ event ก็จะใช้การนับ แต่บางครั้งความน่าจะเป็นแต่ละอันก็ไม่เท่ากันก็ได้
วิเคราะห์ ในกรณี ball and bin
- มี outcome ที่เป็นไปได้ทั้งหมดกี่ outcome มี n ถัง ลูกบอลลูกแรกมี n ทางเลือก ลูกบอลลูกที่สองมี n ทางเลือก ดังนั้นลูกบอล m ลูกมีทางเลือก n ทาง ได้ |Ω| =
- ความน่าจะเป็นที่ไม่มีถังไหนเกิดการชนเลย
- กรณี m > n ความน่าจะเป็นที่เกิดการชนกันคือ 0
- กรณี m = n ความน่าจะที่เกิดการชนกันคือ เนื่องจากทุก outcome มีความน่าจะเป็นที่เท่ากัน ความน่าจะเป็นที่จะได้ outcome ใดๆ คือ 1/ ถ้า n = m ความน่าจะเป็นที่ไม่มี collision ลูกบอลลูกแรกมี n ทางเลือก ลูกที่สองมี n-1 ทางเลือก... ดังนั้น outcome ที่ไม่มี collision คือ n! จาก sample space ได n!/ ซึ่งมีค่าน้อยมากๆ กรณี n มีค่ามากขึ้น ซึ่งสามารถแสดงได้ว่า n!/ ≤ 1/
- โดยเฉลี่ยแล้วมีถังว่างกี่ถัง ต้องการหาจำนวนถังว่างซึ่งเป็นตัวแปรสุ่ม ซึ่งจะไม่มีค่าจนกว่าจะได้ทำการทดลอง แต่เราสามารถพูดถึงคุณสมบัติบางอย่างได้บ้างเหมือนกันแม้ว่าจะไม่ได้ทดลอง เวลาพูดถึงตัวแปรสุ่มมีคุณสมบัติอย่างหนึ่งที่มีความหมายคือ ค่า Expectation ของมัน (หรืออาจเรียกว่า ค่าเฉลี่ยตัวแปรสุ่ม)
สำหรับตัวแปรสุ่ม x ใดๆ
:ในการค่าค่า expectation ของจำนวนถังว่างเมื่อมี n ถังลูกบอล m ลูก จะยากมาก เนื่องจากมันขึ้นต่อกันอยู่ ในการวิเคราะห์ จะใช้คุณสมบัติที่สำคัญของ expectation คือ linearity of expectation คือ
สำหรับตัวแปรสุ่ม x,y ใดๆ จะขึ้นต่อกันก็ได้ หรือไม่ขึ้นต่อกันก็ได้ เช่นจำนวนถังว่าง กับจำนวนถังที่ไม่ว่าง
วิเคราะห์หาจำนวนถังว่างเมื่อจำนวนถังเท่ากับจำนวนลูกบอล นิยามตัวแปรสุ่ม ให้ ตัวแปรสุ่ม x แทนจำนวนถังว่าง ให้ตัวแปรสุ่ม xi แทนจำนวนถังว่าง





![{\displaystyle E[x+y]=E[x]+E[y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d60d296237759245c17ebae65ab220c1a61085ac)